Test-driven Web application development with Common Lisp
The intention of this article is to:
- give a tutorial for the workflow of developing outside-in (or top-down) with tests-first
- give an introduction to creating web applications in Common Lisp including some of the available libraries and frameworks
- explain a bit about test-driven development in general
Outside-in with tests-first
Outside-in (or top-down) nor tests-first is something new. Outside-in approach has been done for probably as long as there are computer languages. Similarly for tests-first. This all has been done for a very long time. The Smalltalk community in the 80's, did tests-first. Kent Beck then developed the workflow and discipline of test-driven development (TDD) a little bit later.
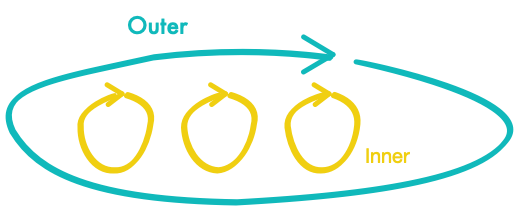
Combining the two makes sense. The idea is that you have two test cycles. An outer test loop which represents an integration or acceptance test, where new test cases (which represent features or parts of a feature) are added incrementally, but only when a previous test case passes. The outer test case fails until the feature was completely integrated and all components were added. And inner test loops that represent all the unit test that are developed in a TDD style for the components to be added.
Adding features incrementally in the context of outside-in means that a feature is developed as a vertical slice of the application rather than building layer by layer horizontally.
This is what we will go though in this article for a single feature of a web application developed from scratch.
At this point I'd like to recommend the book "Growing Object-Oriented Software, Guided by Tests" which talks at length about this topic.
The application here will be developed also incrementally and iteratively. Following the guidelines you should be getting a working application. The iterations shown here don't represent TDD iterations. TDD iterations are much smaller steps but this is hard to really show in writing. For this article it made little sense to really do this. The important thing is to transport the general workflow.
Common Lisp
I wished I had found the Common Lisp world (or the Lisp world in general) earlier. So, I just found Common Lisp somewhen in early 2019. I'm otherwise mostly working in the Java/Scala ecosystem, for almost 20 years. Of course I looked at many other languages and runtimes.
There are many 'new' computer languages these days that have in fact nothing new and are insignificant iterations of something that existed before. In fact nothing new in computer languages came up in the last 40 years or so.
The other thing is, if you want to learn something about programming languages there is no way around having a deeper look at Lisp. The Lisp language is brilliantly simple and expressive. A really practical and productive variant is Common Lisp.
Common Lisp is a representative of the Lisp family that has pretty much every language feature you could think of. It's not statically typed in a way like Haskell or OCaml (ML family) is (I don't wanna get into the dynamic vs. static types thingy now). But what I can say is that both variants have existed for more than 40 years and each has it's pros and cons.
Content overview
As already said, we will go through the development in a test-driven outside-in approach where we will slice vertically through the application and implement a feature with a full integration test and inner unit tests. We will have a look at the following things:
- Getting to the web / Intro
- Project start
- Adding the blog feature
- Conclusion
Getting to the web / Intro
I had the opportunity to work with a few web frameworks in the Java world. From pure markup extension frameworks like JSP over MVC frameworks like Play or Grails to component based server frameworks like Vaadin and Tapestry until I finally have settled with Wicket, which I now work with since 2008.
The frameworks I worked with are usually based on the Java Servlet technology specification (this more or less represents and is an abstraction to the HTTP server and some session handling), which they pretty much all have in common. On top of the Java Servlets are the web frameworks which all enforce certain workflows, patterns and principles. The listed frameworks are a mixture of pure view frameworks and frameworks that also provide data persistence. They provide a routing mechanism and everything needed to make the user interface (UI). Some do explicit separation according to MVC with appropriate folder structures on 'views', 'controllers', 'models' while others do this less explicit. Of course many of those frameworks are opinionated to some degree. But since they usually have many contributors and maintainers the opinions are flattened and less expressive.
The Common Lisp ecosystem regarding web applications is very diverse. There are many framework approaches considering the relatively small community of Common Lisp. The server abstraction exists in form of a self-made opinionated abstraction layer called Clack which allows to use a set of available HTTP servers.
Those are the frameworks I have had a look at: Weblocks, Lucerne, Radiance, Caveman2.
The listed frameworks either base on Clack or directly on the defacto standard HTTP server Hunchentoot. Pretty much all frameworks allow to define REST styled and static routes.
I am not aware of a framework that adds or enforces MVC ('model', 'view', 'controllers'). So if you want MVC you'll have to come up with something yourself (which we'll do here in a very simple form).
The HTML generation is either based on a Django clone called Djulia or is done using one of the brilliant HTML generation libraries for Common Lisp cl-who (for HTML 4) and Spinneret (for HTML 5). Those libraries are HTML DSLs that allow you to code 'HTML' as Lisp code and hence it is compiled, can be type checked and debugged (if needed). Very powerful.
I think the only framework that enforces the use of Djulia is Lucerne. The others don't lock you in on something.
All frameworks also do some convenience wrapping of the request/response for easier access to parameters.
The only one that creates some 'model' abstractions for views is Weblocks. The only one that adds data persistence is Caveman2. But this is just some glue code that you get as convenience. The same libraries can be used in other frameworks.
The most complete one for me seemed to be Caveman2. It also sets up configuration, and creates test and production environments. But the documentation situation is not so good for Caveman2 (and/or Ningle which Caveman2 is based on). I really had a hard time finding things. The other framework documentations are better. However, since the frameworks for a large part glue together libraries it is possible to look at the documentation for those libraries directly. The documantation for Hunchentoot server, cl-who, Spinneret, etc. are sufficiently complete.
The web application we will be developing during this article is based on an old web page design of mine that I'd like to revive. The web application will primarily be about a 'blog' feature that allows blog posts be written in HTML or Markdown and stored as files. The application will pick them up and convert them on the fly (in case of Markdown).
The web application is based on the following libraries (web application relevant only):
- a simple self-made MVC like structure
- Hunchentoot HTTP server
- Snooze REST routing library. This library is implemented with plain CLOS and hence can be easily unit tested. We'll see later how this works. I didn't find this easily possible with any other routing definitions of the other frameworks.
- cl-who for HTML generation, because this old web page is heavy on HTML 4. Otherwise I had used Spinneret.
- 3bmd for Markdown to HTML conversion.
- xml-emitter for generating XML. Used for the Atom feed generation.
- local-time for dealing with date and time formats. Conversions from timestamp to string and vise-versa.
- log4cl a logging library.
- fiveam as unit test library.
- cl-mock a mocking library
The project is hosted on GitHub. So you can checkout the sources yourself. The life web page is available here.
Project start
Since this was my first web project with Common Lisp I had to do some research for how to integrate and run the server and add routes, etc. This is where the scaffolding that frameworks like Caveman2 produce are appeciated.
But, once you know how that works you can start a project from scratch. Along the way you can create a template for future projects. (This can also be in combination with one of the mentioned frameworks.)
That means we don't have a lot of setup to start with. We create a project folder and a src and tests folder therein. That's it. We'll add an ASDF based project/system definition as we go along.
To get started and since we use a test-driven approach we'll start with adding an integration (or acceptance) test for the blog feature.
In order to add tests that are part of a full test suite we'll start creating an overall 'all-tests' test suite. Create a new Lisp buffer/file and add the following code and save it as tests/all-tests.lisp:
(defpackage :cl-swbymabeweb.tests
(:use :cl :fiveam)
(:export #:run!
#:all-tests
#:nil
#:test-suite))
(in-package :cl-swbymabeweb.tests)
(def-suite test-suite
:description "All catching test suite.")
(in-suite test-suite)This is an empty fiveam test package that just defines an empty test suite. It will help us later when creating the ASDF test system as we can point it to this 'all-tests' suite and it'll automatically run all tests of the application.
Adding the blog feature
We will excercise the integration test cycle with the blog page. There are a few use cases for the blog page where we take one that we will go through. The tests need to make sure that all components involved with serving this page are properly integrated and are operational.
The outer test loop
As already said, we have two test cycles. An outer and inner cycle. The outer test cycle represent the integration or acceptance tests while the inner the unit tests. While working on the unit tests it is possible to go back to the outer test for verifications. But the goal is to have the outer test fail until all the inner work is done so that the outer test can act as a guide and a safety net. The outer test cases are added incementally, feature by feature (or maybe also parts of a feature). While all code is developed and refined iteratively in the TDD workflow.
The blog index page is shown when a request goes to the path /blog. On this path the last available blog post is to be selected and displayed.
Let's start with the integration test and create a new Lisp buffer/file, save it as tests/it-routing.lisp and add the following code:
(defpackage :cl-swbymabeweb-test
(:use :cl :fiveam)
(:local-nicknames (:dex :dexador))
(:import-from #:cl-swbymabeweb
#:start
#:stop))
(in-package :cl-swbymabeweb-test)
(def-suite it-routing
:description "Routing integration tests."
:in cl-swbymabeweb.tests:test-suite)
(in-suite it-routing)
(def-fixture with-server ()
(start :address "localhost")
(sleep 0.5)
(unwind-protect
(&body)
(stop)
(sleep 0.5)))
(test handle-blog-index-route
"Test integration of blog - index."
(with-fixture with-server ()
(is (str:containsp "<title>Manfred Bergmann | Software Development | Blog"
(dex:get "http://localhost:5000/blog")))))Let's go through it. It creates a new test package and a new test suite. The :in cl-swbymabeweb.tests:test-suite adds this test suite to the all-tests test suite that we've created before.
The test handle-blog-index-route is a full cycle integration test that uses dexador HTTP client to run a request against the server and expect a certain page title which must be part of the result HTML. Of course, more assertions should be added to make this a proper acceptance test. The intention of the test, and of the feature should be fully clear at this stage. For simplicity reasons we'll more or less just test the routing and the overall integration of components. This test though doesn't create any hint about the architecture of the application or about the inner components. The architecture is carved out step by step by following the flow of calls or data (outside-in).
Since fiveam does not support before or after setup/cleanup functionality we have to workaround this using a fixture that is defined by def-fixture. The fixture will start and stop the HTTP server and in between run code that is the body of with-fixture. We also want to wrap all calls in unwind-protect in order to force shutting down the server as cleanup procedure even if the &body raises an error which would otherwise unwind the stack and the HTTP server would keep running which had consequences on the next test we run.
Now, as part of adding this test we define a few things that don't exist yet. For example do we define a package called cl-swbymabeweb where we import start and stop from. Those start and stop functions obviously do start and stop the web server, so the package cl-swbymabeweb should be an application entry package that does those things.
This is part of what tests-first and TDD does, it acts as the first user of the production code and so defines how the interface should look like from an API user perspective.
When evaluating this buffer/file (I use sly-eval-buffer in Sly, or C-c C-k when the file was saved) we realize (from error messages) that there are some missing packages. So in order to at least get this compiled we have to load the dependencies using quicklisp. Here this would be :dexador, :fiveam and :str (string library).
We also have to create the defined package cl-swbymabeweb and add stubs (for now) for the startand stop functions. That's what we do now. Create a new buffer/file, add the following code as the minimum code to make the integration test compile, evaluate and save it under src/main.lisp.
(defpackage :cl-swbymabeweb
(:use :cl)
(:export #:start
#:stop))
(in-package :cl-swbymabeweb)
(defun start (&key address))
(defun stop ())We can now go into the test package in the REPL by doing (in-package :cl-swbymabeweb-test) and run the test where we will see the following output:
CL-SWBYMABEWEB-TEST> (run! 'handle-blog-index-route)
Running test HANDLE-BLOG-INDEX-ROUTE X
Did 1 check.
Pass: 0 ( 0%)
Skip: 0 ( 0%)
Fail: 1 (100%)
Failure Details:
--------------------------------
HANDLE-BLOG-INDEX-ROUTE in IT-ROUTING [Test integration of blog - index.]:
Unexpected Error: #<USOCKET:CONNECTION-REFUSED-ERROR #x30200389ACBD>
Error #<USOCKET:CONNECTION-REFUSED-ERROR #x30200389ACBD>.
--------------------------------So, of course. Dexador is trying to connect to the server, but there is no server running. The start/stop functions are only stubs. This is OK. It is expected.
In order for the integration test to do it's job and test the full integration we still have a bit more work to do here before we move on. The HTTP server should be working at least. Let's do that now:
Add the following to src/main.lisp on top of the start function:
(defvar *server* nil)For the start function we'll change the signature like this in order to be able to also specify a different port: &key (port 5000) (address "0.0.0.0"). Finally we'll now start the server like so in start:
(defun start (&key (port 5000) (address "0.0.0.0") &allow-other-keys)
(log:info "Starting server.")
(when *server*
(log:info "Server is already running."))
(unless *server*
(setf *server*
(make-instance 'hunchentoot:easy-acceptor
:port port
:address address))
(hunchentoot:start *server*)))This code will make sure that there is no server instance currently being set and if not it will create a server instance and start it.
As a general dependency we use log4cl, a logging framework.
The stop function can be implemented like this:
(defun stop ()
(when *server*
(log:info "Stopping server.")
(prog1
(hunchentoot:stop *server*)
(log:debug "Server stopped.")
(setf hunchentoot:*dispatch-table* nil)
(setf *server* nil))))After 'quickloading' log4cl and hunchentoot and running the test again we will see the following output instead:
CL-SWBYMABEWEB-TEST> (run! 'handle-blog-index-route)
Running test HANDLE-BLOG-INDEX-ROUTE
<INFO> [21:35:21] cl-swbymabeweb (start) - Starting server.
::1 - [2020-09-07 21:35:22] "GET /blog HTTP/1.1" 404 339 "-"
"Dexador/0.9.14 (Clozure Common Lisp Version 1.12 DarwinX8664); Darwin; 19.6.0"
X
<INFO> [21:35:22] cl-swbymabeweb (stop) - Stopping server.
Did 1 check.
Pass: 0 ( 0%)
Skip: 0 ( 0%)
Fail: 1 (100%)
Failure Details:
--------------------------------
HANDLE-BLOG-INDEX-ROUTE in IT-ROUTING [Test integration of blog - index.]:
Unexpected Error: #<DEXADOR.ERROR:HTTP-REQUEST-NOT-FOUND #x3020032527FD>
An HTTP request to "http://localhost:5000/blog" returned 404 not found.
<html><head><title>404 Not Found</title></head><body><h1>Not Found</h1>
The requested URL /blog was not found on this server.<p><hr><address>
<a href='http://weitz.de/hunchentoot/'>Hunchentoot 1.3.0</a>
<a href='http://openmcl.clozure.com/'>
(Clozure Common Lisp Version 1.12 DarwinX8664)</a>
at localhost:5000</address></p></body></html>.
--------------------------------This looks a lot better. The test still fails, which is good and expected. But the server works and responds with 404 for a request to http://localhost:5000/blog.
The test will fail until the server responds with some HTML that contains the expected page title. In order to have the right page title we'll still have some work to do. So now is the time to move towards the inner test loops and develop the inner components in a TDD style. The inner unit tests should of course all pass.
ASDF - a quick detour
But before we do that, and since we still can remember what files and libraries we added to make this all work we should setup an ASDF system that we'll expand as we go along.
For a quick recall, ASDF is the de-facto standard to define Common Lisp systems (or projects if you want). It allows to define library dependencies, source dependencies, tests, and a lot of other metadata.
So create a new buffer/file, save it as cl-swbymabeweb.asd in the root folder of the project and add the following:
(defsystem "cl-swbymabeweb"
:version "0.1.1"
:author "Manfred Bergmann"
:depends-on ("hunchentoot"
"uiop"
"log4cl"
"str")
:components ((:module "src"
:components
((:file "main"))))
:description ""
:in-order-to ((test-op (test-op "cl-swbymabeweb/tests"))))
(defsystem "cl-swbymabeweb/tests"
:author "Manfred Bergmann"
:depends-on ("cl-swbymabeweb"
"fiveam"
"dexador"
"str")
:components ((:module "tests"
:components
((:file "all-tests")
(:file "it-routing" :depends-on ("all-tests"))
)))
:description "Test system for cl-swbymabeweb"
:perform (test-op (op c)
(symbol-call :fiveam :run!
(uiop:find-symbol* '#:test-suite
'#:cl-swbymabeweb.tests))))This defines the necessary ASDF system and test system to fully load the project to the system so far. When the project is in a folder where asdf can find it (like ~/common-lisp) then it can be loaded into the image by:
;; load (and compile if necessary) the production code
(asdf:load-system "cl-swbymabeweb")
;; load (and compile if necessary) the test code
(asdf:load-system "cl-swbymabeweb/tests")
;; run the tests
(asdf:test-system "cl-swbymabeweb/tests")Notice test-system vs. load-system. Since Common Lisp (CL) is image based, ASDF is a facility that can load a full project into the CL image. Keeping the system definition up-to-date is a bit combersome because loading the system must be performed on a clean image to really see if it works or not and if all dependencies are named proper. This is something that must be tried manually on a clean image. I usually do this by issuing sly-restart-inferior-lisp with loading the system, test system and finally testing the test system. When that works it is quite easy to continue working on a project which is merely just:
- open Emacs
- run Sly/Slime REPL
load-system(also the test system if tests should be run) of the project to work on.
Until here we have a ditrectory structure like this:
.
├── cl-swbymabeweb.asd
├── src
│ └── main.lisp
└── tests
├── all-tests.lisp
└── it-routing.lispI need to mention that the ASDF systems we defined explicitely name the source files and dependencies. ASDF can also work in a different mode where it can determine source dependencies according to the :use directive in the defined packages that are spread in files (I tend to use one package per file). This mode then just requires the root source file definition and it can sort out the rest. Look in the ASDF documentation for package-inferred-system if you are interessted.
The inner test loops
Now we will move on to the inner components. The first component that is hit by a request is the routing. We have to define which requests, request paths are handled by what and how. As mentioned earlier most frameworks come with a routing mechnism that allows defining routes. We will use Snooze for this. The difference between Snooze and other URL router frameworks is more or less that routes are defined using plain Lisp functions in Snooze and HTTP conditions are just Common Lisp conditions. The author says: "Since you stay inside Lisp, if you know how to make a function, you know how to make a route. There are no regular expressions to write or extra route-defining syntax to learn.". The other good thing is that the routing can be easily unit tested.
URL routing / introducing the MVC controller

Of course we will start with a test for the routing. There will also be a new architectural component in the play, the MVC controller. The URL routing is still a component heavily tied to system boundary as it has to deal with HTTP inputs and outputs and reponse codes. In order to apply separation of concerns and single responsibility (SRP) we make the routing responsible for collecting all relevant input from the HTTP request and pass it on to the controller. At this stage we have to establish a contract between the router and the controller. So we define the input, expected output of the controller as we see fit from our level of perspective in the router. The output also includes the errors the controller may raise. All this is primarily carved out during developing the routing tests.
So let's put together the first routing test. Create a new buffer/file, save it as tests/routes-test.lisp and put the following in:
(defpackage :cl-swbymabeweb.routes-test
(:use :cl :fiveam :cl-mock :cl-swbymabeweb.routes)
(:export #:run!
#:all-tests
#:nil))
(in-package :cl-swbymabeweb.routes-test)
(def-suite routes-tests
:description "Routes unit tests"
:in cl-swbymabeweb.tests:test-suite)
(in-suite routes-tests)
(test blog-route-index
"Tests the blog index route.")This just defines an empty test. But we require a new library called cl-mock. It is a mocking framework.
Why do we need mocking here? Well, we want to use a collaborating component, the controller. But we'd want to defer the implementation of the controller until it is necessary. That is not now. The mock allows us to define the interface to the controller without having to implement it. This also allows us to stay focused on the routing and the controller interface definition. We don't need to be distracted with any controller implementation details.
In order to get the test package compiled we have to quickload two things, that is snooze and cl-mock. We also have to create the 'package-under-test' package. This can for now simply look like so (save as src/routes.lisp):
(defpackage cl-swbymabeweb.routes
(:use :cl :snooze))
(in-package :cl-swbymabeweb.routes)Once the test code compiles and we can actually run the empty test (use in-package and run! as above) we can move on to implementing more of the test.
One thing to remember is to update the ASDF system definition with the new files we added and library dependencies. However, in order to not interrupt the workflow I'd like to defer that until we can make a clear head again. The best time might be when we are done with the unit tests for the routes.
Now, let's add the following to the test function blog-route-index:
(with-mocks ()
(answer (controller.blog:index) (cons :ok ""))
(with-request ("/blog") (code)
(is (= 200 code))
(is (= 1 (length (invocations 'controller.blog:index))))))with-mocks is a macro that comes with cl-mock. Any mocking code must be wrapped inside it. To actually mock a function call we use the answer macro which is also part of cl-mock. The use of answer in our test code basically means: answer a call to the function (controller.blog:index) with the result (cons :ok ""). Since the controller does not yet exist we did define the interface for it here and now. This is how we want the controller to work. We did define that there should be a dedicated controller for the blog family of pages. We also defined that if there is no query parameter we want to use the index function of the controller to deliver an appropriate result. The result should be a cons consisting of an atom (_car) and a string (_cdr). The car indicates success or failure result (the exact failure atoms we don't know yet). The cdr contains a string for either the generated HTML content or a failure description. answer doesn't call the function, it just records what has to happen when the function is called.
Let's move on: the with-request macro (below) is copied from the snooze sources. It takes a request path and fills the code parameter with the result of the route handler. In the body of the with-request macro we can verify the code with an expected code. Also we want to verify that the request handler actually called the controller index function by checking the number of invocations that cl-mock recorded.
Now to compile and run the test there are a few things missing. First of all the with-request macro. Copy the following to routes-test.lisp:
(defmacro with-request ((uri
&rest morekeys
&key &allow-other-keys) args
&body body)
(let ((result-sym (gensym)))
`(let* ((snooze:*catch-errors* nil)
(snooze:*catch-http-conditions* t)
(,result-sym
(multiple-value-list
(snooze:handle-request
,uri
,@morekeys)))
,@(loop for arg in args
for i from 0
when arg
collect `(,arg (nth ,i ,result-sym))))
,@body)))Also we need a stub of the controller. Create a new buffer/file, save it as src/controllers/blog.lisp and add the following:
(defpackage :cl-swbymabeweb.controller.blog
(:use :cl)
(:export #:index)
(:nicknames :controller.blog))
(in-package :cl-swbymabeweb.controller.blog)
(defun index ())The test and the overall code should now compile. When running the test we see that the HTTP result code is 404 instead of the expected 200. We also see that
(LENGTH (INVOCATIONS 'CL-SWBYMABEWEB.CONTROLLER.BLOG:INDEX))evaluated to 0. Which means that the controller index function was not called.
This is good, because there is no route defined in src/routes.lisp. In contrast to the outer loop tests, which we shouldn't solve immediatele, we should of course solve this one. So let's add a route now to make the test 'green'. Add this to routes.lisp:
(defroute blog (:get :text/html)
(controller.blog:index))This defines a route with a root path of /blog. It defines that it must be a GET request and that the output has a content-type of text/html.
When we now evaluate the new route and run the test again we have both is assertions passing.
At this point we should add a failure case as well. What could be a failure for the index route? The index is supposed to take the last available blog entry and deliver it. Having no blog entry is not an error I would say, rather the HTML content that the controller delivers should be empty, or should contain a simple string saying "there are no blog entries". So the only error that could be returned here is some kind of internal error that was raised somewhere which bubbles up through the controller to the route handler.
Let's add an additional test:
(test blog-route-index--err
"Tests the blog index route. internal error"
(with-mocks ()
(answer (controller.blog:index) (cons :internal-error "Foo"))
(with-request ("/blog") (code)
(is (= 500 code))
(is (= 1 (length (invocations 'controller.blog:index)))))))Running the test has one assertion failing. The code is actually 200, but we expect it to be 500. In order to fix it we have to add some error handling and differentiate between :ok and :internal-error results from the controller. Let's do this, change the route definition to this:
(defroute blog (:get :text/html)
(let ((result (controller.blog:index)))
(case (car result)
(:ok (cdr result))
(:internal-error (http-condition 500 (cdr result))))))This will make all existing tests green. But I'd like to add another test for a scenario where the controller result is undefined, or at least not what the router expects. I'd like to prepare for any unforseen that might happen on this route handler so that the response can be a defined proper error code. So add this test:
(test blog-route-index--err-undefined-controller-result
"Tests the blog index route.
internal error when controller result is undefined."
(with-mocks ()
(answer (controller.blog:index) nil)
(with-request ("/blog") (code)
(is (= 500 code))
(is (= 1 (length (invocations 'controller.blog:index)))))))When executing this test the response code is a 204, which represents 'no content'. And indeed, this is correct. When the controller result is nil the router handler will also return nil because there is no case that handles this controller result, so the function runs through without having defined an explicit return, which then makes the function return nil. So we have to change the router code a bit to handle this and more cases. Change the route definition to:
(defroute blog (:get :text/html)
(handler-case
(let ((result (controller.blog:index)))
(case (car result)
(:ok (cdr result))
(:internal-error (http-condition 500 (cdr result)))
(t (error "Unknown controller result!"))))
(error (c)
(let ((error-text (format nil "~a" c)))
(log:error "Route error: " error-text)
(http-condition 500 error-text)))))The outer handler-case catches any error that may happen and produces a proper code 500. Additionally it logs the error text. The case has been enhanced with a 'otherwise' handler which actually produces an error condition that is caught in the outer handler-case.
When running the tests again we should be fine.
The tests of the router don't actually test the string content (_cdr_) of the controller result because it's irrelevant to the router. It's important to only test the responsibilities of the unit-under-test. Any tests that go beyond the responsibilities, or the public interface of the unit-under-test leads to more rigidity and the potential is much higher that tests fail and must be fixed when changes are made to production code elsewhere.
We are now done with this feature slice in the router. It is now a good time to bring the ASDF system definition up to date. Add the new library dependencies: snooze, cl-mock. Also change the :components section to look like this:
:components ((:module "src"
:components
((:module "controllers"
:components
((:file "blog")))
(:file "routes")
(:file "main"))))This adds the 'controllers' sub-folder as a sub component that can name additional source files under it. When done, restart the REPL, load both systems and also run test-system. At this point this should look like this:
Did 7 checks.
Pass: 6 (85%)
Skip: 0 ( 0%)
Fail: 1 (14%)The only expected failing test is the integration test. Though the fail reason is still 404 'Not Found'. This is because we have not yet registered the route with the HTTP server. But I'd like to postpone this for when we have implemented the controller.
The blog controller
Before we go to implement the tests for the controller and the code for the controller itself we have to think a bit about the position of this component in relation to the other components and what the responsibilies of the blog controller are. In the MVC pattern it has the role of controlling the view. It also has the responsibility to generate the data, the model, that the view needs to do its job. The view is responsible to produce a representation in a desired output format. The model usually consist of a) the data to present to the user and b) the attributes to control the view components for visibility (enabled/disabled, etc.).
In our case we want the view to create a HTML page representation that contains the text and images of a blog entry, the blog navigation, and all the rest of the page. So the model must contain everything that the view needs in order to generate all this.
Let's have a look at this diagram:
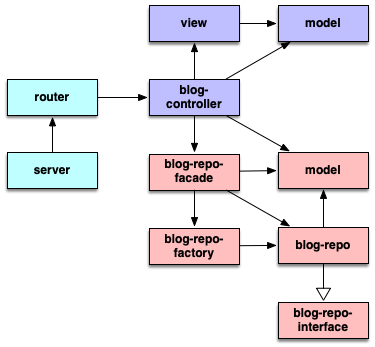
The blog controller should not have to deal with loading the blog entry data from file. This is the responsibility of the blog repository. Stripping out this functionality into a separate component has a few advantages. It keeps the controller code small and clean maintaining single responsibility. This is reflected in the tests, they will be simple and clean as well. The blog-repo will have to be mocked for the tests. The interface to the blog-repo will also be defined when implementing the tests for the blog controller on a use-case basis. The blog-repo as being in a separate area of the application will have its own model that can carry the data of the blog entries. The controller s job will be to map all relevant data from the blog-repo model to the view model. A model separation is important here for orthogonality. Both parts, the blog-repo and the controller / view combo should be able to move and develop separately and in their own pace. Of course the controller, as user of the blog-repo has to adapt to changes of the blog-repo interface and model. But this should only be necessary in one direction.
The purpose of blog-repo-factory is to be able to switch the kind of blog-repo implementation for different environments. It allows us to make the controller use a different blog-repo for test and production environment. The controller will only access the blog-repo through the blog-repo-facade which is a simplified interface to the blog-repo that hides away all the inner workings of the blog repository. So the controller will only use two things: the blog-repo-facade and the blog repo model. This simplified interface to the blog repository will also be simple to mock in the controller tests as we will see shortly.
The arrows in this diagram mark the direction of dependencies. The router has an inward dependency on the controller. The controller in turn has a dependency on the view and model because it must create both. The controller also has a dependency on the blog-repo-facade and on the model of the blog-repo. But none of this should have a dependency on the controller. Nor should the controller know about anything happening in the router or deal with HTTP codes directly. This is the responsibility of the router.
The MVC pattern at first wasn't actually a pattern, or at least not officially known as a pattern. It was added to Smalltalk as a way to program UIs in the late 70's and only later MVC was adopted by other languages and frameworks. It allows a decoupling and a separation of concerns. Different teams can work on view, controller and model code. It also allows better testability and a higher reusability of the code. Use-cases grouped as MVC have a high cohesion and a lower coupling.
It's interesting, the 70's to 90's were amazing times. Pretty much all technological advancements of programming languages and patterns of computer science come from this time frame. Structured programming, object-oriented programming, functional programming, statically typed languages (Standard ML) and type inference (Hindley-Milner) were invented then. It was a time of open-minded exploration and ideas.
-- detour end
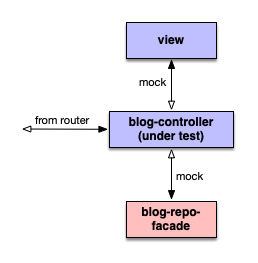
Again, we start with test code, the plain blog controller test package. Save this as tests/blog-controller-test.lisp:
(defpackage :cl-swbymabeweb.blog-controller-test
(:use :cl :fiveam :cl-mock)
(:export #:run!
#:all-tests
#:nil))
(in-package :cl-swbymabeweb.blog-controller-test)
(def-suite blog-controller-tests
:description "Tests for blog controller"
:in cl-swbymabeweb.tests:test-suite)
(in-suite blog-controller-tests)The first test is already a bummer. It is slightly more complex than anything we had so far. But it won't get a lot more complex. It's not trivial to write how this slowly develops applying TDD using the red-green-refactor phases. So I'm just pasting the complete test with all additional needed data. But of course this was developed in the classic TDD style.
(defparameter *expected-page-title-blog*
"Manfred Bergmann | Software Development | Blog")
(defparameter *blog-model* nil)
(test blog-controller-index-no-blog-entry
"Test blog controller index when there is no blog entry available"
(setf *blog-model*
(make-instance 'blog-view-model
:blog-post nil))
(with-mocks ()
(answer (blog-repo:repo-get-latest) (cons :ok nil))
(answer (blog-repo:repo-get-all) (cons :ok nil))
(answer (view.blog:render *blog-model*) *expected-page-title-blog*)
(is (string= (cdr (controller.blog:index)) *expected-page-title-blog*))
(is (= 1 (length (invocations 'view.blog:render))))
(is (= 1 (length (invocations 'blog-repo:repo-get-all))))
(is (= 1 (length (invocations 'blog-repo:repo-get-latest))))))The first, simpler test assumes that no blog entry exists. Let's go through it:
We have now two things that come into play. It's 1) the blog-repo-facade here represented as blog-repo package and 2) the blog view package view.blog. The blog views s render function will produce HTML output. We will mock the view generation and will answer with the pre-defined *expected-page-title-blog*. The blog view will also need a model, represented as *blog-model* parameter.
Again we need to setup mocks using with-mocks macro. The answer calls represent the interfaces and function calls the controller should do to the blog-repo in order to a) retrieve all blog entries (blog-get-all) which is internally triggered through the call blog-get-latest. So the way the blog-repo works is that in order to retrieve the latest entry all entries must be available which must be collected before. Again we define an output interface of the blog-repo to be a cons with an atom as car and a result as the cdr. The two blog-repo facade calls both return with :ok but contain an empty result. This is not an error. The view has to render appropriately, which is not tested here. Also again, the controller tests do only test the expected behavior of the controller which is more or less: generate the model for the view, pass it to the view and take a response from the view.
The view.blog:render function takes as parameter the blog model and should return some HTML which contains the expected page title. The *blog-model* is a class structure which is here initialized kind of empty (nil represents empty).
The assertions make sure that a call to controller.blog:index actually returns the expected page title as cdr and also that all expected functions have been called.
In order for this to compile we have to add a few things. Create a new buffer/file and add the following code for the stub of the blog-repo-facade and save it as src/blog-repo.lisp:
(defpackage :cl-swbymabeweb.blog-repo
(:use :cl)
(:nicknames :blog-repo)
(:export ;; facade for repo access
#:repo-get-latest
#:repo-get-all))
(in-package :cl-swbymabeweb.blog-repo)
(defun repo-get-latest ()
"Retrieves the latest entry of the blog.")
(defun repo-get-all ()
"Retrieves all available blog posts.")Also we have to add the view stub. Create a new buffer/file, save it as src/views/blog.lisp and add the following:
(defpackage :cl-swbymabeweb.view.blog
(:use :cl)
(:nicknames :view.blog)
(:export #:render
#:blog-view-model))
(in-package :cl-swbymabeweb.view.blog)
(defclass blog-view-model ()
((blog-post :initform nil
:initarg :blog-post
:reader model-get-blog-post)
(all-blog-posts :initform '()
:initarg :all-blog-posts
:reader model-get-all-posts)))
(defun render (view-model))This package also defines the model class. The blog-view-model is the aggregated model that is passed in from the controller. The blog-post and all-blog-posts slots model up the 'to-be-displayed' blog entry and all available blog entries which is relevant for the navigation view component. To have a separation from the blog-repo model data (orthogonality) we will add separate model classes that are used only for the view. We will do this shortly.
Considering the dependencies we have two options of where to define the model. It's either right here (this works if we have a simple model class), or we define it in a separate package. In case we have more model classes and more complex ones this would be the better approach.
There is one addition we have to add to the test package. Add the following to right below the :export:
(:import-from #:view.blog
#:blog-view-model)We explicitly import only the things we really need. This is the minimal code to get all compiled but the tests should still fail. So we have to implement some logic to the index function of the controller.
In order for the blog controller code in src/controllers/blog.lisp to know the view functions we should import the :view.blog package and then we have to implement some code to make the tests pass.
We just have to look at the test expectations and implement them. An aspect of TDD I haven't talked about is the faking and cheating one can do in order to get the tests green (pass) as quickly as possible. When the tests pass we can refactor and replace the cheating with some 'real' code. Until now I have presented you full implemententations of the production code that fit to the test expectations. But a TDD cycle moves in fast paced iterations with only small changes from red to green, then refactor, then from green to red for a new test case to restart the cycle. The cycle from red to green can contain cheating. This is because we want feedback as quickly as possible about what we did is either good or no good. When we cheat, this 'good' means just that we meet the current test expectation. Iteration for iteration we add new expectations that at some point can't be cheated anymore. This workflow that switches between test code and production code very rapidly and the immediate feedback we get puts us kind of into a symbiosis between the test code and the production code. The realization and the feeling of the code building up this way is enormously satisfying. The fact that you can just concentrate on small fractions of code but know that there is a outer protection (outer test loop) is a big relief.
-- detour end
So now I'll introduce a bit of cheating that just makes the one existing test case and all assertions pass. As I said this actually builds up in much smaller steps. And eventually of course we need to get rid of the cheating.
So, replace the index function with the following implementation and also add the other small functions.
(defun index ()
(let ((lookup-result (blog-repo:repo-get-latest))
(all-posts-result (blog-repo:repo-get-all)))
(make-controller-result
:ok
(view.blog:render
(make-view-model (cdr lookup-result) (cdr all-posts-result))))))
(defun make-controller-result (first second)
"Convenience function to create a new controller result.
But also used for visibility of where the result is created."
(cons first second))
(defun make-view-model (the-blog-entry all-posts)
(make-instance 'blog-view-model
:blog-post nil
:all-blog-posts nil))This is partly cheated insofar as the view model is generated with hardcoded nil values just as the tests expect it. When we compile this we're getting warnings shown for unused variables the-blog-post and all-posts. Those warnings should be treated seriously. We'll fix them shortly.
To better reveil the intention of how the controller works, and the output it generates we add a function make-controller-result that can generate the result (which after all is just a cons).
When we run the tests they will all pass:
Running test BLOG-CONTROLLER-INDEX-NO-BLOG-ENTRY ....
Did 4 checks.
Pass: 4 (100%)
Skip: 0 ( 0%)
Fail: 0 ( 0%)When we now add another test case we will have no other choice as to remove the cheating in order to make the tests pass. We will see now. For the new test case we will need quite a bit additional production code, even if it's just stubs (more or less) but we need to get things compiled in order to even only run the new test. Add the following test case:
(defparameter *blog-entry* nil)
;; 12 o'clock on the 20th September 2020
(defparameter *the-blog-entry-date* (encode-universal-time 0 0 12 20 09 2020))
(test blog-controller-index
"Test blog controller for index which shows the latest blog entry"
(setf *blog-entry*
(blog-repo:make-blog-entry "Foobar"
*the-blog-entry-date*
"<b>hello world</b>"))
(setf *blog-model*
(make-instance 'blog-view-model
:blog-post
(blog-entry-to-blog-post *blog-entry*)
:all-blog-posts
(mapcar #'blog-entry-to-blog-post (list *blog-entry*))))
(with-mocks ()
(answer (blog-repo:repo-get-latest) (cons :ok *blog-entry*))
(answer (blog-repo:repo-get-all) (cons :ok (list *blog-entry*)))
(answer (view.blog:render model-arg)
(progn
(assert
(string= "20 September 2020"
(slot-value (slot-value model-arg 'view.blog::blog-post)
'view.blog::date)))
(assert
(string= "20-09-2020"
(slot-value (slot-value model-arg 'view.blog::blog-post)
'view.blog::nav-date)))
*expected-page-title-blog*))
(is (string= (cdr (controller.blog:index)) *expected-page-title-blog*))
(is (= 1 (length (invocations 'view.blog:render))))
(is (= 1 (length (invocations 'blog-repo:repo-get-all))))
(is (= 1 (length (invocations 'blog-repo:repo-get-latest))))))The parameter *blog-entry* is set up with the model from the blog-repo, which we have to define still. Otherwise it is similar to the previous test case. The difference is that we expect the blog-repo now to actually get us blog entries which are mapped to the view model and passed on to the view to generate the display. We also use a new functionality of the answer macro. It can do pattern matching on the provided function parameter and so we can validate the date and nav-date formatting (we will add the model for this shortly). We also pre-define a timestamp with the *the-blog-entry-date* parameter which we require to be stable for the test case.
Now let's add the missing code to get this compiled. Stay close as we have to modify a few files.
To src/blog-repo.lisp add the following class which represents the blog model:
(defclass blog-entry ()
((name :initform ""
:type string
:initarg :name
:reader blog-entry-name
:documentation "the blog name, the filename minus the date.")
(date :initform nil
:type fixnum
:initarg :date
:reader blog-entry-date
:documentation "universal timestamp")
(text :initform ""
:type string
:initarg :text
:reader blog-entry-text
:documentation "The HTML representation of the blog text.")))
(defun make-blog-entry (name date text)
(make-instance 'blog-entry :name name :date date :text text)) The make-blog-entry is a convenience function to more easily create a blog-entry instance. This class structure has three slots. The name represents the name of the blog entry. The date is the date (timestamp, type fixnum) of the last update of the blog entry. And text is the HTML representation of the blog entry text. We don't go into detail about the blog text. The blog-repo takes care of this detail. What is important is that it delivers the text in a representational format that is immediately usable. There may be different strategies at play in the blog-repo that are able to convert from different sources to HTML. As initially pointed out the goal should be to allow plain HTML and Markdown texts. So at this point blog-repo is a black box for us. We use the data as is.
Then we'll have to add some additional exports in this package so that the class itself and the reader accessors can be used from importing packages.
(:export #:make-blog-entry
#:blog-entry-name
#:blog-entry-date
#:blog-entry-text
;; facade for repo access
#:repo-get-latest
#:repo-get-all)In src/controllers/blog.lisp we need the following additions:
(defun blog-entry-to-blog-post (blog-entry)
"Converts `blog-entry' to `blog-post'.
This function makes a mapping from the repository
blog entry to the view model blog entry."
(log:debug "Converting post: " blog-entry)
(when blog-entry
(make-instance 'blog-post-model
:name (blog-entry-name blog-entry)
:date (format-timestring nil
(universal-to-timestamp
(blog-entry-date blog-entry))
:format
'((:day 2) #\Space
:long-month #\Space
(:year 4)))
:nav-date (format-timestring nil
(universal-to-timestamp
(blog-entry-date blog-entry))
:format
'((:day 2) #\-
(:month 2) #\-
(:year 4)))
:text (blog-entry-text blog-entry))))I'll explain in a bit what this does. Suffice to say for now that this is the function that maps the data from a blog-entry data structure to the blog-post-model data structure (which we'll define next) as used in the blog-view-model.
This function uses date-time formatting, so we need an import for the functions format-timestring and universal-to-timestamp. Those are date-time conversion functions that allows the Common Lisp get-universal-time timestamp to be converted to a string using a defined format. Import and quickload the package local-time for that. Additionally we need the controller to import :blog-repo so that is has access to the blog-entry and the readers accessors.
We also need to define another view model class that represents the blog entry to be displayed. Add the following to src/views/blog.lisp:
(defclass blog-post-model ()
((name :initform ""
:type string
:initarg :name)
(date :initform ""
:type string
:initarg :date)
(nav-date :initform ""
:type string
:initarg :nav-date)
(text :initform ""
:type string
:initarg :text)))This class is relatively close to the blog-repo class blog-entry. The controller function blog-entry-to-blog-post makes the mapping from one to the other. The view has a different responsibility than the blog-repo has. For example has the blog-post-model an additional slot, the nav-date. It is used in the 'recents' navigation and must present the blog post create/update date in a different string format than is shown in the full blog post display. Generally we use a string type for the date and nav-date slots here because the instance that controls how something is displayed is the controller.
So blog-entry-to-blog-post makes a full mapping from a blog-entry to a blog-post-model with all that is actually needed for the view. With this we make the view a relatively dump component that just shows what the controller wants. The controller test also defines the date formats to be used. Those formats and date strings as displayed by the view are validated in the answer call. Let's have a look at this in more detail:
(answer (view.blog:render model-arg)
(progn
(assert
(string= "20 September 2020"
(slot-value (slot-value model-arg 'view.blog::blog-post)
'view.blog::date)))
(assert
(string= "20-09-2020"
(slot-value (slot-value model-arg 'view.blog::blog-post)
'view.blog::nav-date)))
*expected-page-title-blog*))The answer macro captures the function call arguments, so we can give the argument a name and check on its values. In our case we want to assert that the date strings are of the correct format, which are two different formats. The nav-date for example has to be a bit more condensed than the standard date format. After all answer has to still return something so we use progn which returns the last expression. Since we did not export the slots of blog-view-model and blog-post-model we use the double colon :: to access them. We didn't export those symbols because no one except the view itself needs to access them. This is a bit of a grey area because we tap into a private area of the model data structures. On the other hand it would be good to control and verify the format of the date string. So we choose to accept to live with possible test failures when the structure of the model changes.
With the last addition the code compiles now. So we can run the new test. The test of course fails with:
BLOG-CONTROLLER-INDEX in BLOG-CONTROLLER-TESTS
[Test blog controller for index which shows the latest blog entry]:
Unexpected Error: #<SIMPLE-ERROR #x3020039689ED>
NIL has no slot named CL-SWBYMABEWEB.VIEW.BLOG::DATE..This is logical. Because we still have our cheating in place that creates a view model with hard coded nil values. So the mocks don't have any effect due to this.
To make the tests pass we have to add the proper implementation of the make-view-model function in the controller code (see above). Replace the function with this:
(defun make-view-model (the-blog-entry all-posts)
(make-instance 'blog-view-model
:blog-post
(blog-entry-to-blog-post the-blog-entry)
:all-blog-posts
(mapcar #'blog-entry-to-blog-post all-posts)))This will now pass the blog-repo blog entry through the mapping function for the single blog-post slot as well as for all available blog posts generated by mapcar for all-blog-posts. Compiling this will now also remove the warnings we have had with this previously as the two function arguments are now used. Running the tests again now will give us a nice:
Running test BLOG-CONTROLLER-INDEX ....
Did 4 checks.
Pass: 4 (100%)
Skip: 0 ( 0%)
Fail: 0 ( 0%)Taking a step back and reflect
The MVC blog controller is a relatively complex and central piece in this application. Let's take a step back for a moment and recapture what we have done and how we should continue.
The controller is using two collaborators to do its work. Those two are the blog-repo and the view. Both are not part of the controller unit and hence must be tested reparately. The controller as the driver of the functionality wants to control how to talk to the two collaborators. So the controller tests define the interface which is then implemented in the controller code and in both the blog-repo and the view. For now the collaborators are only implemented with stubs so that the mocking can be applied. Since the controller is the only 'user' of the two collaborating components it can more or less freely define the interface as it requires it. Would there be more 'users' there would be a bit more of 'pulling' from each 'user' so that eventually the interface would be more of a compromise or just had more functionality. We have also decided that the controller controls what and how the view displays the data. This was done for the date formats that are being displayed in the view.
Before we move on to working on the view we should recheck the outer loop test to verify that it still fails. Also now is a good time to register the routing on the HTTP server.
The registration of the routes on the HTTP server is a missing piece in the full integration. The error the test provokes should get more accurate the closer we get to the end. So we're closing that gap now. To recall, the integration test raises a 404 'Not Found' error on the /blog route. That can be 'fixed' because we have implemented the route.
Extend the src/routes.lisp with the following function:
(defun make-routes ()
(make-hunchentoot-app))This function must also be exported: (:export #:make-routes).
Then in src/main.lisp import this function:
(:import-from #:cl-swbymabeweb.routes
#:make-routes)and change the start function to this (partly):
(unless *server*
(push (make-routes)
hunchentoot:*dispatch-table*)
(setf *server*
(make-instance 'hunchentoot:easy-acceptor
:port port
:address address))
(hunchentoot:start *server*)))The make-routes function will create route definitions that can be applied on Hunchentoot HTTP server *dispatch-table*. This is a feature of snooze. It can do this for other servers as well.
Running the integration test now will give a different result.
<ERROR> [13:20:51] cl-swbymabeweb.routes routes.lisp (blog get text/html) -
Route error: CL-SWBYMABEWEB.ROUTES::ERROR-TEXT:
"The value \"Retrieves the latest entry of the blog.\"
is not of the expected type LIST."This is a bit odd. What's going on?
When looking at it more closely it makes sense. This is in fact great. It shows us that many parts are still missing for a full integration of all components. The text 'Retrieves the latest entry of the blog.' is returned by the function repo-get-latest of the blog-repo facade. Since it defines no explicit return it will implicitly return the only element in the function, which here is the docstring. But later, in the controller, the return of the repo-get-latest is expected to be a cons (the error says LIST, but a list is a list of cons elements) but apparently it is no cons. So when trying to access elements of the cons with car or cdr we will see this error.
This tells us that there is still quite a bit of work left. We will later fix the integration test without fully implementing the blog-repo.
Also a good time to bring the ASDF system up-to-date. Add all the new files and library dependencies. Add the src/views/blog.lisp component similarly as we added the controller component. Also add src/blog-repo.lisp. It should be defined before the view and the controller definitions due to the direction of dependency. Also add local-time library dependency.
To check if the system definitions work you can always do those four steps:
- restart the inferior lisp process.
- load the default system (
asdf:load-system) and fix missing components if it doesn't compile. - load the test system. Fix missing components if necessary.
- test the test system (
asdf:test-system).
The blog view
We are free to generate the view representation as we like. We can use any library we like to. We could even mix those. What the controller expects the view to deliver is HTML as a string. This is the only contract we have. What are our options to generate HTML? We could use:
- a templating library. Templating libraries are based on template files which represent pages or smaller page components. A page template is usually composed of smaller component templates. Templates also allow inheritance. Templating libraries usually provide 'language' constructs that allow 'structured programming' (to some extend) in the template, like for loops, if/else, etc. The template library then evaluates the template and expands the language constructs to HTML code:
- a DSL that allows to write Lisp code which looks close to HTML constructs. There are a few libraries in Common Lisp that do this. Generally DSLs are relatively easy to create in Common Lisp using macros:
There are a few more options for both variants. If you are curious you can have a look at awesome-cl.
We are choosing cl-who for this project mainly because I like the expressivness of Lisp code. When I can write HTML this way, the better. In addition, since it is Lisp code I get an almost immediate feedback about the validity of the code in the editor when compiling a code snippet. For larger projects however the templating variant may be a better choice because of the separation between the HTML and the backing code it provides, even though the template language weakens this separation. But yet it might be easier to non-coders to work with the HTML template files.
If we recall, we had created a package for the view where we just created a stub of the render function, and also we did define the view model classes that the controller instantiates and fills with data. But we had not created tests for this because the render function of the view was mocked in the controller test.
Now, when resuming here we first create a test. Testing the view is a bit tricky. In the most simple form you can only make string comparisons of what is expected to be in the generated HTML. Some frameworks come with sophisticated test functionality that goes far beyond just testing in the HTML string representation (Apache Wicket is such a candidate). A stop gap solution to allow more convenient testing is to use some form of HTML parser utility wrapped behind a framework facade. But we're not developing a framework here (this could be a nice project). Neither does any existing Common Lisp web framework has such a functionality. So we're stuck with just doing some string comparisons.
Let's start with a test package for the view. Create a new buffer/file, add the following and save it as tests/blog-view-test.lisp:
(defpackage :cl-swbymabeweb.blog-view-test
(:use :cl :fiveam :view.blog)
(:export #:run!
#:all-tests
#:nil))
(in-package :cl-swbymabeweb.blog-view-test)
(def-suite blog-view-tests
:description "Blog view tests"
:in cl-swbymabeweb.tests:test-suite)
(in-suite blog-view-tests)This is nothing new. Now let's create a first test. To keep things simple we start with a test that expects a certain bit of HTML to be generated, like the header page title. But we have to supply an instanciated model object to the render function. So there is a bit of test setup needed. This is how it looks:
(defparameter *expected-blog-page-title*
"Manfred Bergmann | Software Development | Blog")
(defparameter *blog-view-empty-model*
(make-instance 'blog-view-model
:blog-post nil
:all-blog-posts nil))
(test blog-view-nil-model-post
"Test blog view to show empty div when there is no blog post to show."
(let ((page-source (view.blog:render *blog-view-empty-model*)))
(is (str:containsp *expected-blog-page-title* page-source))))This test for now has a single assertion. We only check for the existence of the header page title which is defined as a parameter *expected-blog-page-title*. The model passed in to the render function does not contain any blog entry and no list of blog entries for the navigation element.
A proper web framework should provide enough self-tests and building blocks that one can assume a HTML page is structurally correct. We don't do this kind of checking here to keep things simple. A library that could be facilitated for this is Plump, which is a HTML parser library.
When we run this test it of course fails, because for sure the page title is not included in the render output. In fact the render output is nil. Let's change that.
The following production code will make the test pass. One addition though, we have to :use the cl-who library in the blog-view package because we're going to use now the DSL this library provides. We also have to quickload this library first and of course add it to the .asd file eventually.
(defparameter *page-title* "Manfred Bergmann | Software Development | Blog")
(defun render (view-model)
(log:debug "Rendering blog view")
(with-page *page-title*))
(defmacro with-page (title &rest body)
`(with-html-output-to-string
(*standard-output* nil :prologue t :indent t)
(:html
(:head
(:title (str ,title))
(:meta :http-equiv "Content-Type"
:content "text/html; charset=utf-8"))
(:body
,@body))))Adding this code will make the test pass. What does it do? First of all, the render function uses a self-made building block, the macro with-page. The macro allows to pass two things, 1) the page title and 2) it allows to nest additional code as body of the macro. Having a look at the macro we see the use of cl-who. The with-html-output-to-string macro allows embedding a body of DSL structures that are similar to HTML tags. The only difference is that instead of XML tags that enclose an element we use the Lisp syntax to do the same thing. So for example a :html macro can again nest other code in the body the same as a <html></html> XML tag does. Since this is then Lisp code it is compiled as any other Lisp code and hence can also be validated by the compiler, at least as far as the Lisp macro/function structure goes. The (:body ,@body) allows to add more components to the :body which represents the <body></body> HTML tag. The current use of the with-page macro could also look like this:
(with-page "my page title"
(:a :href "http://my-host/foo" :class "my-link-class" (str "my-link-label")))This would be translated to:
<html>
<! head, title, etc. >
<body>
<a href="http://my-host/foo" class="my-link-class">my-link-label</a>
</body>
</html>So cl-who in combination with Lisp macros it is easily possible to build pages, or smaller page components as reusable building blocks that can be nested and composed where needed. This is probably the reason why no, or only few Common Lisp libraries provide this kind of thing out of the box. Because it's so easy to create from scratch. And after all, depending on what you create and in which context, pre-defined macros and framework building blocks may not necessarily represent the domain language you want or need in your application.
Actually I'd like to stop here. You've got a glimpse of how generating HTML components using cl-who and macros works and how the testing can be done. There is of course a lot more work to be done for this application. If you are curious the full project is at GitHub.
But we have one last thing missing before we can recapture. The integration test is still failing. The view code we just added should suffice to make it pass. But as said above at Revisit the outer test loop, the blog-repo in it's incomplete form returns something unusable. So we have to 'fix' that. Change the blog-repo facade functions to this:
(defun repo-get-latest ()
"Retrieves the latest entry of the blog."
(cons :ok nil))
(defun repo-get-all ()
"Retrieves all available blog posts."
(cons :ok nil))This will make the integration test pass, but again, this is a fake.
CL-SWBYMABEWEB-TEST> (run! 'handle-blog-index-route)
Running test HANDLE-BLOG-INDEX-ROUTE
<INFO> [14:39:31] cl-swbymabeweb main.lisp (start) - Starting server.
::1 - [2020-10-03 14:39:31] "GET /blog HTTP/1.1" 200 305 "-"
"Dexador/0.9.14 (Clozure Common Lisp Version 1.12 DarwinX8664); Darwin; 19.6.0"
.
<INFO> [14:39:31] cl-swbymabeweb main.lisp (stop) - Stopping server.
Did 1 check.
Pass: 1 (100%)
Skip: 0 ( 0%)
Fail: 0 ( 0%)It kind of suffices for an integration test, because the blog-repo is part of this integration. But of course when adding more integration tests we would have to come up with something else in which the blog-repo would be fully developed. Checkout the full code in the GitHub project.
With this integration test passing we finalized a full vertical slice of a feature implementation. All relevant components were integrated, even if only as much as needed for this feature (or part of a feature). Any more outer integration tests (which also represent feature integrations) will maybe extend or change the interface to the added components.
Some words on deployment
There are many ways of deploying a web application in Common Lisp. You could for example just open a REPL, load the project using ASDF, or Quicklisp (when it's in an appropriate local folder) and just run the server starter as we did in the integration test.
Another option is to make a simple wrapper script that could look like this:
(ql:quickload :cl-swbymabeweb) ;; requires this project to be in a local folder
;; findable by Quicklisp
(defpackage cl-swbymabeweb.app
(:use :cl :log4cl))
(in-package :cl-swbymabeweb.app)
(log:config :info :sane :daily "logs/app.log" :backup nil)
;; run server hereAnd just save this file as app.lisp in the root folder of the project.
Then just start your Common Lisp like this: sbcl --load app.lisp.
There are also ways to run a remote session using Slync or Swank where you can also do remote debugging, etc.
Conclusion
We've implemented part of a feature of a web application doing a full vertical slice of the application design using an outside-in test-driven approach. While doing that using Common Lisp we've used and looked at test libraries as well as other libraries that help making web applications easier.
But we also didn't talk about many things that are relevant for web applications. Like, how to configure logging in the web server. How to add static routes. How to use sessions and also localization of strings on a per session basis. How to use JavaScript using the awesome Parenscript package that allows writing JavaScript in Common Lisp. There are other references on the web to address those things. Maybe I will also blog about on of these sometime in the future.
So long, thanks for reading.
-
[ACE BASIC 3.0.1 - Variable Arrays and 68000 Compat]
14-05-2026 -
[ACE BASIC 3.0 - Classes IEEE and More]
02-03-2026 -
[ACE BASIC - Structs RTG and More]
16-02-2026 -
[Developing with AI - Understanding the Context]
13-02-2026 -
[ACE BASIC - Closures MUI and More]
10-02-2026 -
[ACE BASIC - GadTools and More]
31-01-2026 -
[ACE BASIC - AGA Screen Support]
27-01-2026 -
[Polymorphism and Multimethods]
02-03-2023 -
[Global Day of CodeRetreat - recap]
07-11-2022 -
[House automation tooling - Part 4 - Finalized]
01-11-2022 -
[House automation tooling - Part 3 - London-School and Double-Loop]
02-07-2022 -
[Modern Programming]
14-05-2022 -
[House automation tooling - Part 2 - Getting Serial]
21-03-2022 -
[House automation tooling - Part 1 - CL on MacOSX Tiger]
07-03-2022 -
[Common Lisp - Oldie but goldie]
18-12-2021 -
[Functional Programming in (Common) Lisp]
29-05-2021 -
[Patterns - Builder-make our own]
13-03-2021 -
[Patterns - Builder]
24-02-2021 -
[Patterns - Abstract-Factory]
07-02-2021 -
[Lazy-sequences - part 2]
13-01-2021 -
[Lazy-sequences]
07-01-2021 -
[Thoughts about agile software development]
17-11-2020 -
[Test-driven Web application development with Common Lisp]
04-10-2020 -
[Wicket UI in the cluster - the alternative]
09-07-2020 -
[TDD - Mars Rover Kata Outside-in in Common Lisp]
03-05-2020 -
[MVC Web Application with Elixir]
16-02-2020 -
[Creating a HTML domain language in Elixir with macros]
15-02-2020 -
[TDD - Game of Life in Common Lisp]
01-07-2019 -
[TDD - classicist vs. London Style]
27-06-2019 -
[Wicket UI in the cluster - reflection]
10-05-2019 -
[Wicket UI in the Cluster - know how and lessons learned]
29-04-2019 -
[TDD - Mars Rover Kata classicist in Scala]
23-04-2019 -
[Burning your own Amiga ROMs (EPROMs)]
26-01-2019 -
[TDD - Game of Life in Clojure and Emacs]
05-01-2019 -
[TDD - Outside-in with Wicket and Scala-part 2]
24-12-2018 -
[TDD - Outside-in with Wicket and Scala-part 1]
04-12-2018 -
[Floating Point library in m68k Assembler on Amiga]
09-08-2018 -
[Cloning Compact Flash (CF) card for Amiga]
25-12-2017 -
[Writing tests is not the same as writing tests]
08-12-2017 -
[Dependency Injection in Objective-C... sort of]
20-01-2011